US9219621B2 - Dynamic rate heartbeating for inter-node status updating - Google Patents
Dynamic rate heartbeating for inter-node status updating Download PDFInfo
- Publication number
- US9219621B2 US9219621B2 US13/425,666 US201213425666A US9219621B2 US 9219621 B2 US9219621 B2 US 9219621B2 US 201213425666 A US201213425666 A US 201213425666A US 9219621 B2 US9219621 B2 US 9219621B2
- Authority
- US
- United States
- Prior art keywords
- nodes
- node
- communications
- program instructions
- operational
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related, expires
Links
Images




Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L12/00—Data switching networks
- H04L12/64—Hybrid switching systems
- H04L12/6418—Hybrid transport
Definitions
- the present invention is related to node status monitoring in distributed computing systems, and more specifically to a scheme of dynamically controlling heartbeat rate and node status thresholds.
- nodes provide independent execution of sub-tasks.
- the status of nodes is tracked.
- Communications and status monitoring may be performed according to a heartbeat-driven messaging scheme.
- Heartbeat messages are typically sent from the nodes to a centralized manager that maintains a record of the status of each node.
- the heartbeat rate and parameters for determining whether nodes and their connections are operational is typically fixed, so that uniformity in determining node status can be presumed.
- the invention provides a node status monitoring method that collects information about transmission delays for communications between the nodes, and determines statistics used to adjust heartbeat rate and/or node status thresholds.
- the method receives messages transmitted periodically among the nodes according to a heartbeat rate, which may be gossip messages transmit between all of the node pairs in the cluster.
- a heartbeat rate which may be gossip messages transmit between all of the node pairs in the cluster.
- Indications of the communications delays of the received messages are stored and are used to compute statistics of a sliding window of the stored communications delays.
- Parameters of the node status monitoring, which are used for determining operational status of the nodes, are adjusted according to the statistics, which may include adjusting the heartbeat rate, the maximum wait time before a message is considered missed, and/or the maximum number of missed messages, e.g., the sequence number deviation, before the node is considered non-operational (down).
- FIG. 1 is a block diagram of a distributed computer system in which techniques according to an embodiment of the present invention are practiced.
- FIG. 2 is a pictorial diagram depicting communication between nodes of a computer system in accordance with an embodiment of the present invention.
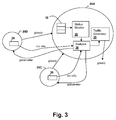
- FIG. 3 is a pictorial diagram showing features of a node status monitoring scheme in accordance with an embodiment of the present invention.
- FIG. 4 is a flowchart of a method in accordance with an embodiment of the present invention.
- the present invention encompasses techniques for monitoring communication status in clusters of nodes within distributed computing systems.
- embodiments of the invention provide mechanisms for determining the operational status of the nodes in the cluster by monitoring communications delays and missed communications between the nodes.
- Messages which may be gossip messages transmitted between each of the node pairs in a cluster as described in the above-incorporated U.S. Patent application “INTER-NODE COMMUNICATION SCHEME FOR NODE STATUS SHARING”, are transmitted at a regular heartbeat rate. The receipt of the messages is timed, and an indication of the communications delay from the other nodes is stored, as well as the sequence number of the most recent message from each node.
- the mean of the communications delay and the average deviation or other indication of a typical deviation value are updated from the measured delay and are used to adjust parameters of the monitoring scheme, which may include the heartbeat rate, the communications delay threshold that is used to determine when a message from another node has been missed, and/or a maximum number of missed messages allowed before a node is considered non-operational (dead). Therefore, the status monitoring scheme of the present invention adapts parameters to the present network and processing loads, without requiring manual adjustments by administrators.
- a first physical processing node 10 A includes a processor core 12 coupled to a memory 14 that stores program instructions for execution by processor 12 .
- the program instructions include program instructions forming computer program products in accordance with embodiments of the invention that provide node status monitoring for either physical processing nodes 10 A- 10 D, virtual processing nodes partitioned within the depicted computer system as will be described in further detail below, or both.
- Processing node 10 A also includes a network interface (NWI) 16 that couples processing node 10 A to a wired, wireless or hybrid network, which may be a standardized network such as Ethernet, or a proprietary network or interconnect bus.
- NWI network interface
- Other processing nodes 10 B- 10 D are of identical construction in the exemplary embodiment, but embodiments of the invention may be practiced
- a distributed computer system in accordance with an embodiment of the present invention will generally include a large number of compute nodes connected via one or more networks.
- the distributed computer system of FIG. 1 also includes other resources such as I/O devices 19 , including graphical display devices, printers, scanners, keyboards, mice, which may be coupled to the network or one of nodes 10 A- 10 D via workstation computers that provide a user interface to administrative personnel and other users.
- Nodes 10 A- 10 D are also coupled to storage devices 18 , for storing and retrieving data and program instructions, such as storing computer program products in accordance with an embodiment of the invention.
- nodes 20 may correspond exactly on a one-to-one basis with processing nodes 10 A- 10 D (and other nodes) of FIG. 1 , or nodes 20 may be partitioned in a different manner as virtual processing nodes.
- a single node 20 may have exclusive use of multiple processing nodes, e.g. nodes 10 A- 10 B, and result in a system having a greater number of virtual nodes than processing nodes, or alternatively, multiple nodes 20 may be implemented on a single processing node, e.g., node 10 A.
- each of nodes 20 represents at least one operating system image and one or more applications executing within the operating system image.
- the entire system as depicted may execute a single application, but sub-tasks within the application are apportioned to the various nodes 20 , which may be identical sub-tasks or different sub-tasks.
- the present invention concerns node status monitoring and communications of node status among nodes within the computer system of FIG. 1 .
- gossip messages and other node status command messages are communicated between nodes 20 and the messages are processed at each node. While the exemplary embodiment uses the same gossip messages described in the above-incorporated U.S. Patent Application, the sharing of status information is not required to practice the present invention, as the statistical analysis and parameter tuning disclosed herein can be applied in node status monitoring schemes that use other types of messages having a predictable pattern, such as centrally broadcast heartbeat pings containing no additional status information.
- operational messages are also passed between nodes 20 , including data and program code transmissions.
- Nodes are generally arranged in a cluster, which is a group of virtual or physical processing nodes organized to perform a particular task or group of tasks, e.g., for a particular customer. As illustrated, communication between nodes in a cluster may be accomplished by direct node to node communications 22 or by next-neighbor communications 24 in which nodes 20 pass along messages to other nodes 20 .
- node-to-node communications do not require that the transmissions take place over a physical network that does not traverse other nodes, and the next-neighbor communications 24 can be used to implement node-to-node communications.
- next-neighbor communications 24 can be used to implement node-to-node communications.
- a central facility for inter-node communication which is distinct from centrally reporting and acting on node status indications.
- the present invention may encompass techniques that use a centralized communication point, such as a star arrangement, while still passing gossip messages in a node-to-node manner with respect to the messaging endpoints.
- a centralized communication point such as a star arrangement
- gossip messages in a node-to-node manner with respect to the messaging endpoints.
- the illustrated embodiment provides a de-centralized communications monitoring system, it is generally preferable not to use a central exchange for messaging.
- Nodes 20 A- 20 C each send gossip messages to all other nodes in the cluster and include a status monitor 36 that determines whether a gossip message from another node has not been received within a predetermined period, i.e. a maximum communications delay threshold value.
- the data provided to the status monitor is stored in a table 32 or other database as the messages are received, details of which are described in the above-referenced U.S.
- Status monitors 36 in each of the nodes send message reception information, which may be aggregated as individual statistics at each of the nodes, to a central analysis block 38 , which computes statistics such as the mean and average deviation of the communications delay values over the node cluster and computes parameters such as the heartbeat rate, the maximum communications delay threshold and the maximum missed packet count from the statistics.
- the parameters are sent to the other nodes 20 B- 20 C, in the illustration, to tune the heartbeat rate used by traffic generator 39 in each of the nodes, and/or to set the thresholds used to decide whether to mark a node as up or down when messages are not received from that node.
- the sample size in the exemplary embodiment is 1000, and the default values of communications thresholds are pre-biased to high values and then change to lower values as sample data is accumulated.
- ⁇ T MEAS and the mean deviation D is: D ( t ) 0.125 *D ( t ⁇ t )+0.875 *ERR
- the statistics are continuously updated according to the above formulas and are used to set the maximum number of missed messages allowed until a node is marked as down. If, for example, a node is generating messages every 100 ms, the average communications time is 70 ms and the average variation is 30 ms attributed to network traffic, communications errors and other overhead, then as the time increases without receiving a next packet from the node, the probability that the missed communication was caused by normal fluctuations decreases and the probability that the node is down increases.
- Gossip messages are transmitted between node pairs in the cluster (step 49 ).
- the messages are received at the nodes and the communications delay and message sequence number are recorded (step 50 ), and in the particular embodiment other information such as the status of the other nodes obtained from the gossip messages.
- a message communications delay is greater than the maximum delay threshold, i.e., a message is not received after a predetermined time period (decision 51 )
- the message is marked as missed (step 52 ).
- the missed sequence numbers for the missing message has exceeded a maximum count of missed messages (step 53 )
- the node from which the expected gossip message was not received is marked as down (step 54 ).
- the communications delay is less than or equal to the maximum delay threshold (decision 51 ) if the message is received from a node that is marked as down (decision 55 ), then the node is marked as up (step 56 ).
- the collected communications information is sent to the data analysis block (step 57 ) and the statistics of the communications delay are determined (step 58 ).
- the node status monitoring parameters are determined from the statistics, e.g., the heartbeat rate, maximum delay threshold and maximum missed message count (step 59 ) and the computed parameters are sent to the nodes (step 60 ).
- the process of steps 49 - 60 is repeated until the system is shutdown or the scheme is otherwise terminated (decision 61 ).
- the present invention may be embodied as a system, method, and/or a computer program product.
- a computer program product may be embodied in firmware, an image in system memory or another memory/cache, stored on a fixed or re-writable media such as an optical disc having computer-readable code stored thereon. Any combination of one or more computer readable medium(s) may be used to store the program instructions in accordance with an embodiment of the invention.
- the computer readable medium may be a computer readable signal medium or a computer readable storage medium.
- a computer readable storage medium may be, for example, but not limited to, an electronic, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus, or device, or any suitable combination of the foregoing.
- the computer readable storage medium would include the following: an electrical connection having one or more wires, a portable computer diskette, a hard disk, a random access memory (RAM), a read-only memory (ROM), an erasable programmable read-only memory (EPROM or Flash memory), an optical fiber, a portable compact disc read-only memory (CD-ROM), an optical storage device, a magnetic storage device, or any suitable combination of the foregoing.
- a computer readable storage medium may be any tangible medium that can contain, or store a program for use by or in connection with an instruction execution system, apparatus, or device.
- a computer readable signal medium may include a propagated data signal with computer readable program code embodied therein, for example, in baseband or as part of a carrier wave. Such a propagated signal may take any of a variety of forms, including, but not limited to, electro-magnetic, optical, or any suitable combination thereof.
- a computer readable signal medium may be any computer readable medium that is not a computer readable storage medium and that can communicate, propagate, or transport a program for use by or in connection with an instruction execution system, apparatus, or device.
- Program code embodied on a computer readable medium may be transmitted using any appropriate medium, including but not limited to wireless, wireline, optical fiber cable, RF, or any suitable combination of the foregoing.
- Computer program code for carrying out operations for aspects of the present invention may be written in any combination of one or more programming languages, including an object oriented programming language such as Java, Smalltalk, C++ or the like and conventional procedural programming languages, such as the “C” programming language or similar programming languages.
- object oriented programming language such as Java, Smalltalk, C++ or the like
- conventional procedural programming languages such as the “C” programming language or similar programming languages.
Abstract
A scheme for monitoring node operational status according to communications transmits messages periodically according to a heartbeat rate among the nodes. The messages may be gossip messages containing the status of the other nodes in the pairs, are received at the nodes and indications of the communications delays of the received messages are stored, which are used to compute statistics of the stored communications delays. Parameters of the node status monitoring, which are used for determining operational status of the nodes, are adjusted according to the statistics, which may include adjusting the heartbeat rate, the maximum wait time before a message is considered missed, and/or the maximum number of missed messages, e.g., the sequence number deviation, before the node is considered non-operational (down).
Description
The present Application is a Continuation of U.S. patent application Ser. No. 12/959,568, filed on Dec. 3, 2010 and claims priority thereto under 35 U.S.C. §120. The disclosure of the above-referenced parent U.S. Patent Application is incorporated herein by reference.
The present U.S. Patent Application is related to co-pending U.S. patent applications Ser. No. 12/959,581 entitled “ INTER-NODE COMMUNICATION SCHEME FOR NODE STATUS SHARING” and Ser. No. 12/959,556 entitled “ENDPOINT-TO-ENDPOINT COMMUNICATIONS STATUS MONITORING ” filed contemporaneously herewith and having at least one common inventor and assigned to the same Assignee, the disclosures of which are incorporated herein by reference.
1. Field of the Invention
The present invention is related to node status monitoring in distributed computing systems, and more specifically to a scheme of dynamically controlling heartbeat rate and node status thresholds.
2. Description of Related Art
In large-scale distributed computer systems, such as those using distributed software models to perform tasks, multiple nodes provide independent execution of sub-tasks. In order to keep such a system operational, and further, to provide for proper operation of distributed applications that use the multiple nodes to perform various tasks, the status of nodes is tracked.
In particular, in order to assign tasks to nodes, and in order to ensure that a node is available to communicate with to perform a task, the operational status of the nodes and their ability to communicate with the other nodes must be monitored.
Communications and status monitoring may be performed according to a heartbeat-driven messaging scheme. Heartbeat messages are typically sent from the nodes to a centralized manager that maintains a record of the status of each node. The heartbeat rate and parameters for determining whether nodes and their connections are operational is typically fixed, so that uniformity in determining node status can be presumed.
The invention provides a node status monitoring method that collects information about transmission delays for communications between the nodes, and determines statistics used to adjust heartbeat rate and/or node status thresholds.
The method receives messages transmitted periodically among the nodes according to a heartbeat rate, which may be gossip messages transmit between all of the node pairs in the cluster. Indications of the communications delays of the received messages are stored and are used to compute statistics of a sliding window of the stored communications delays. Parameters of the node status monitoring, which are used for determining operational status of the nodes, are adjusted according to the statistics, which may include adjusting the heartbeat rate, the maximum wait time before a message is considered missed, and/or the maximum number of missed messages, e.g., the sequence number deviation, before the node is considered non-operational (down).
The foregoing and other objectives, features, and advantages of the invention will be apparent from the following, more particular, description of the preferred embodiments of the invention, as illustrated in the accompanying drawings.
The novel features believed characteristic of the invention are set forth in the appended claims. The invention itself, however, as well as a preferred mode of use, further objectives, and advantages thereof, will best be understood by reference to the following detailed description of the invention when read in conjunction with the accompanying Figures, wherein like reference numerals indicate like components, and:
The present invention encompasses techniques for monitoring communication status in clusters of nodes within distributed computing systems. In particular, embodiments of the invention provide mechanisms for determining the operational status of the nodes in the cluster by monitoring communications delays and missed communications between the nodes. Messages, which may be gossip messages transmitted between each of the node pairs in a cluster as described in the above-incorporated U.S. Patent application “INTER-NODE COMMUNICATION SCHEME FOR NODE STATUS SHARING”, are transmitted at a regular heartbeat rate. The receipt of the messages is timed, and an indication of the communications delay from the other nodes is stored, as well as the sequence number of the most recent message from each node. The mean of the communications delay and the average deviation or other indication of a typical deviation value are updated from the measured delay and are used to adjust parameters of the monitoring scheme, which may include the heartbeat rate, the communications delay threshold that is used to determine when a message from another node has been missed, and/or a maximum number of missed messages allowed before a node is considered non-operational (dead). Therefore, the status monitoring scheme of the present invention adapts parameters to the present network and processing loads, without requiring manual adjustments by administrators.
Referring now to FIG. 1 , a distributed computer system in accordance with an embodiment of the present invention is shown. A first physical processing node 10A includes a processor core 12 coupled to a memory 14 that stores program instructions for execution by processor 12. The program instructions include program instructions forming computer program products in accordance with embodiments of the invention that provide node status monitoring for either physical processing nodes 10A-10D, virtual processing nodes partitioned within the depicted computer system as will be described in further detail below, or both. Processing node 10A also includes a network interface (NWI) 16 that couples processing node 10A to a wired, wireless or hybrid network, which may be a standardized network such as Ethernet, or a proprietary network or interconnect bus. Other processing nodes 10B-10D are of identical construction in the exemplary embodiment, but embodiments of the invention may be practiced
in asymmetric distributed systems having nodes with differing features. Although only four compute nodes 10A-10D are illustrated, a distributed computer system in accordance with an embodiment of the present invention will generally include a large number of compute nodes connected via one or more networks. The distributed computer system of FIG. 1 also includes other resources such as I/O devices 19, including graphical display devices, printers, scanners, keyboards, mice, which may be coupled to the network or one of nodes 10A-10D via workstation computers that provide a user interface to administrative personnel and other users. Nodes 10A-10D are also coupled to storage devices 18, for storing and retrieving data and program instructions, such as storing computer program products in accordance with an embodiment of the invention.
Referring now to FIG. 2 , communication between multiple nodes 20 of the distributed computer system of FIG. 1 is shown. As mentioned above, nodes 20 may correspond exactly on a one-to-one basis with processing nodes 10A-10D (and other nodes) of FIG. 1 , or nodes 20 may be partitioned in a different manner as virtual processing nodes. For example, a single node 20 may have exclusive use of multiple processing nodes, e.g. nodes 10A-10B, and result in a system having a greater number of virtual nodes than processing nodes, or alternatively, multiple nodes 20 may be implemented on a single processing node, e.g., node 10A. In the present invention, each of nodes 20 represents at least one operating system image and one or more applications executing within the operating system image. In general, the entire system as depicted may execute a single application, but sub-tasks within the application are apportioned to the various nodes 20, which may be identical sub-tasks or different sub-tasks. The present invention concerns node status monitoring and communications of node status among nodes within the computer system of FIG. 1 .
In the exemplary embodiment, as described in the above-incorporated U.S. Patent Application “INTER-NODE COMMUNICATION SCHEME FOR NODE STATUS SHARING”, gossip messages and other node status command messages are communicated between nodes 20 and the messages are processed at each node. While the exemplary embodiment uses the same gossip messages described in the above-incorporated U.S. Patent Application, the sharing of status information is not required to practice the present invention, as the statistical analysis and parameter tuning disclosed herein can be applied in node status monitoring schemes that use other types of messages having a predictable pattern, such as centrally broadcast heartbeat pings containing no additional status information. In the present embodiment, operational messages are also passed between nodes 20, including data and program code transmissions. Nodes are generally arranged in a cluster, which is a group of virtual or physical processing nodes organized to perform a particular task or group of tasks, e.g., for a particular customer. As illustrated, communication between nodes in a cluster may be accomplished by direct node to node communications 22 or by next-neighbor communications 24 in which nodes 20 pass along messages to other nodes 20. While the description of the particular embodiments of the invention below describes the node status and gossip communications taking place node-to-node as opposed to from nodes to a centralized status facility, it is understood that node-to-node communications do not require that the transmissions take place over a physical network that does not traverse other nodes, and the next-neighbor communications 24 can be used to implement node-to-node communications. Further, as alternative to the illustrated communications is to use a central facility for inter-node communication, which is distinct from centrally reporting and acting on node status indications. Therefore, the present invention may encompass techniques that use a centralized communication point, such as a star arrangement, while still passing gossip messages in a node-to-node manner with respect to the messaging endpoints. However, since the illustrated embodiment provides a de-centralized communications monitoring system, it is generally preferable not to use a central exchange for messaging.
Referring now to FIG. 3 , a node status monitoring scheme in accordance with an embodiment of the invention is illustrated. Nodes 20A-20C each send gossip messages to all other nodes in the cluster and include a status monitor 36 that determines whether a gossip message from another node has not been received within a predetermined period, i.e. a maximum communications delay threshold value. The data provided to the status monitor is stored in a table 32 or other database as the messages are received, details of which are described in the above-referenced U.S. Patent Application “GOSSIPING SCHEME FOR NODE STATUS SHARING.” Status monitors 36 in each of the nodes send message reception information, which may be aggregated as individual statistics at each of the nodes, to a central analysis block 38, which computes statistics such as the mean and average deviation of the communications delay values over the node cluster and computes parameters such as the heartbeat rate, the maximum communications delay threshold and the maximum missed packet count from the statistics. The parameters are sent to the other nodes 20B-20C, in the illustration, to tune the heartbeat rate used by traffic generator 39 in each of the nodes, and/or to set the thresholds used to decide whether to mark a node as up or down when messages are not received from that node.
In the exemplary embodiment, the mean round-trip communications time estimate (MRT) is computed according to:
MRT(t)=0.875*MRT(t−Δt)+0.125*T MEAS
where Δt is the measurement interval and TMEAS is the most-recently measured round-trip communications time. The sample size in the exemplary embodiment is 1000, and the default values of communications thresholds are pre-biased to high values and then change to lower values as sample data is accumulated. The communications error is computed according to:
ERR=|MRT|−T MEAS
and the mean deviation D is:
D(t)=0.125*D(t−Δt)+0.875*ERR
MRT(t)=0.875*MRT(t−Δt)+0.125*T MEAS
where Δt is the measurement interval and TMEAS is the most-recently measured round-trip communications time. The sample size in the exemplary embodiment is 1000, and the default values of communications thresholds are pre-biased to high values and then change to lower values as sample data is accumulated. The communications error is computed according to:
ERR=|MRT|−T MEAS
and the mean deviation D is:
D(t)=0.125*D(t−Δt)+0.875*ERR
The statistics are continuously updated according to the above formulas and are used to set the maximum number of missed messages allowed until a node is marked as down. If, for example, a node is generating messages every 100 ms, the average communications time is 70 ms and the average variation is 30 ms attributed to network traffic, communications errors and other overhead, then as the time increases without receiving a next packet from the node, the probability that the missed communication was caused by normal fluctuations decreases and the probability that the node is down increases. If, for example, at t=200 ms, the communications is not received, there is a high probability (approximately 0.99) that the missed packet is due to the node being down and not due to normal communications variation, and so the other nodes are polled to determine if they have indications that the node is alive. If the other nodes do not have indications that the node is alive, then at t=800 ms, for example, the node can be presumed dead.
Referring now to FIG. 4 , a node status monitoring method in accordance with an embodiment of the present invention is illustrated. Gossip messages are transmitted between node pairs in the cluster (step 49). The messages are received at the nodes and the communications delay and message sequence number are recorded (step 50), and in the particular embodiment other information such as the status of the other nodes obtained from the gossip messages. If a message communications delay is greater than the maximum delay threshold, i.e., a message is not received after a predetermined time period (decision 51), the message is marked as missed (step 52). If the missed sequence numbers for the missing message has exceeded a maximum count of missed messages (step 53), the node from which the expected gossip message was not received is marked as down (step 54). Otherwise, if the communications delay is less than or equal to the maximum delay threshold (decision 51) if the message is received from a node that is marked as down (decision 55), then the node is marked as up (step 56). After the node status processing is complete, the collected communications information is sent to the data analysis block (step 57) and the statistics of the communications delay are determined (step 58). The node status monitoring parameters are determined from the statistics, e.g., the heartbeat rate, maximum delay threshold and maximum missed message count (step 59) and the computed parameters are sent to the nodes (step 60). The process of steps 49-60 is repeated until the system is shutdown or the scheme is otherwise terminated (decision 61).
As noted above, the present invention may be embodied as a system, method, and/or a computer program product. A computer program product may be embodied in firmware, an image in system memory or another memory/cache, stored on a fixed or re-writable media such as an optical disc having computer-readable code stored thereon. Any combination of one or more computer readable medium(s) may be used to store the program instructions in accordance with an embodiment of the invention. The computer readable medium may be a computer readable signal medium or a computer readable storage medium. A computer readable storage medium may be, for example, but not limited to, an electronic, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus, or device, or any suitable combination of the foregoing. More specific examples (a non-exhaustive list) of the computer readable storage medium would include the following: an electrical connection having one or more wires, a portable computer diskette, a hard disk, a random access memory (RAM), a read-only memory (ROM), an erasable programmable read-only memory (EPROM or Flash memory), an optical fiber, a portable compact disc read-only memory (CD-ROM), an optical storage device, a magnetic storage device, or any suitable combination of the foregoing.
In the context of the present application, a computer readable storage medium may be any tangible medium that can contain, or store a program for use by or in connection with an instruction execution system, apparatus, or device. A computer readable signal medium may include a propagated data signal with computer readable program code embodied therein, for example, in baseband or as part of a carrier wave. Such a propagated signal may take any of a variety of forms, including, but not limited to, electro-magnetic, optical, or any suitable combination thereof. A computer readable signal medium may be any computer readable medium that is not a computer readable storage medium and that can communicate, propagate, or transport a program for use by or in connection with an instruction execution system, apparatus, or device. Program code embodied on a computer readable medium may be transmitted using any appropriate medium, including but not limited to wireless, wireline, optical fiber cable, RF, or any suitable combination of the foregoing.
Computer program code for carrying out operations for aspects of the present invention may be written in any combination of one or more programming languages, including an object oriented programming language such as Java, Smalltalk, C++ or the like and conventional procedural programming languages, such as the “C” programming language or similar programming languages.
While the invention has been particularly shown and described with reference to the preferred embodiments thereof, it will be understood by those skilled in the art that the foregoing and other changes in form and details may be made therein without departing from the spirit and scope of the invention. time before a message is considered missed, and/or the maximum number of missed messages, e.g., the sequence number deviation, before the node is considered non-operational (down).
Claims (12)
1. A method for determining node operating status among a cluster of nodes of a computer system, the method comprising:
transmitting gossip messages directly between pairs of nodes of the cluster, the gossip messages containing an indication of operational status of nodes of the cluster other than the nodes corresponding to the pair of nodes between which the gossip message is communicated, wherein the transmitting is performed periodically according to a heartbeat rate;
receiving the gossip messages at a receiving one of the corresponding pair of nodes and storing indications of communications delays for the gossip messages;
computing statistics of the communications delay for the gossip messages, wherein the computing computes a mean and mean deviation of the communications delays, and wherein the mean of the communications delay is a mean round-trip communications time (MRT) computed according to the formula MRT(t)=0.875*MRT(t−Δt)+0.125*TMEAS, where Δt is a period corresponding to the heartbeat rate and TMEAS is the most-recently measured round-trip communications time, and wherein the mean deviation of the communications delay D is computed according to D(t)=0.125*D(t−Δt)+0.875*ERR, where ERR=|MRT|−TMEAS;
adjusting parameters for node status monitoring according to the computed statistics, wherein the adjusting parameters of the node status monitoring comprises adjusting a threshold maximum number of missed receptions of the receiving used to determine whether a node is operational according to the mean round-trip communications time and the mean deviation of the communications delay; and
monitoring the operational status of the nodes according to the indications of communications delay, the parameters, and the operational status of the other nodes in the cluster as communicated by the gossip messages.
2. The method of claim 1 , wherein the adjusting parameters of the node status monitoring comprises adjusting a rate of the transmitting in conformity with the computed statistics.
3. The method of claim 1 , wherein the adjusting parameters of the node status monitoring comprises adjusting a maximum wait time used to determine whether a node is operational when one or more of the gossip messages transmitted by the transmitting has not been received.
4. The method of claim 1 , wherein the adjusting parameters of the node status monitoring comprises adjusting a maximum number of missed receptions of the receiving used to determine whether a node is operational.
5. A computer system comprising a processing cluster including a plurality of physical or virtual processing nodes, the computer system comprising at least one processor for executing program instructions and at least one memory coupled to the processor for executing the program instructions, wherein the program instructions are program instructions for determining node operating status among a cluster of the physical or virtual processing nodes, the program instructions comprising program instructions for:
transmitting gossip messages directly between pairs of nodes of the cluster, the gossip messages containing an indication of operational status of nodes of the cluster other than the nodes corresponding to the pair of nodes between which the gossip message is communicated, wherein the transmitting is performed periodically according to a heartbeat rate;
receiving the gossip messages at a receiving one of the corresponding pair of nodes and storing indications of communications delays for the messages;
computing statistics of the communications delay for the gossip messages, wherein the program instructions for computing compute a mean and mean deviation of the communications delays, and wherein the program instruction for computing compute the mean of the communications delay as a mean round-trip communications time (MRT) according to the formula MRT(t)=0.875*MRT(t−Δt)+0.125*TMEAS, where Δt is a period corresponding to the heartbeat rate and TMEAS is the most-recently measured round-trip communications time, and compute the mean deviation of the communications delay D according to D(t)=0.125*D(t−Δt)+0.875*ERR, where ERR=|MRT|−TMEAS;
adjusting parameters for node status monitoring according to the computed statistics, wherein the program instructions for adjusting the parameters of the node status monitoring adjust a threshold maximum number of missed receptions of the receiving used to determine whether a node is operational according to the mean round-trip communications time and the mean deviation of the communications delay; and
monitoring the operational status of the nodes according to the indications of communications delay, the parameters, and the operational status of the other nodes in the cluster as communicated by the gossip messages.
6. The computer system of claim 5 , wherein the program instructions for adjusting parameters of the node status monitoring adjust a rate of the transmitting in conformity with the computed statistics.
7. The computer system of claim 5 , wherein the program instructions for adjusting parameters of the node status monitoring adjust a maximum wait time used to determine whether a node is operational when one or more of the gossip messages transmitted by the transmitting has not been received.
8. The computer system of claim 5 , wherein the program instructions for adjusting parameters of the node status monitoring adjust a maximum number of missed receptions of the receiving used to determine whether a node is operational.
9. A computer program product comprising a computer-readable storage device storing program instructions for execution within a computer system, the computer system comprising a processing cluster including a plurality of physical or virtual processing modes, wherein the program instructions are program instructions for determining node operating status among a cluster of the physical or virtual processing nodes, the program instructions comprising program instructions for:
transmitting gossip messages directly between pairs of nodes of the cluster, the gossip messages containing an indication of operational status of nodes of the cluster other than the nodes corresponding to the pair of nodes between which the gossip message is communicated, wherein the transmitting is performed periodically according to a heartbeat rate;
receiving the gossip messages at a receiving one of the corresponding pair of nodes and storing indications of communications delays for the messages;
computing statistics of the communications delay for the gossip messages, wherein the program instructions for computing compute a mean and mean deviation variance of the communications delays, and wherein the program instruction for computing compute the mean of the communications delay as a mean round-trip communications time (MRT) according to the formula MRT(t)=0.875*MRT(t−Δt)+0.125*TMEAS, where Δt is a period corresponding to the heartbeat rate and TMEAS is the most-recently measured round-trip communications time, and compute the mean deviation of the communications delay D according to D(t)=0.125*D(t−Δt)+0.875*ERR, where ERR=|MRT|−TMEAS;
adjusting parameters for node status monitoring according to the computed statistics, wherein the program instructions for adjusting the parameters of the node status monitoring adjust a threshold maximum number of missed receptions of the receiving used to determine whether a node is operational according to the mean round-trip communications time and the mean deviation of the communications delay; and
monitoring the operational status of the nodes according to the indications of communications delay, the parameters, and the operational status of the other nodes in the cluster as communicated by the gossip messages.
10. The computer program product of claim 9 , wherein the program instructions for adjusting parameters of the node status monitoring adjust a rate of the transmitting in conformity with the computed statistics.
11. The computer program product of claim 9 , wherein the program instructions for adjusting parameters of the node status monitoring adjust a maximum wait time used to determine whether a node is operational when one or more of the gossip messages transmitted by the transmitting has not been received.
12. The computer program product of claim 9 , wherein the program instructions for adjusting parameters of the node status monitoring adjust a maximum number of missed receptions of the receiving used to determine whether a node is operational.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/425,666 US9219621B2 (en) | 2010-12-03 | 2012-03-21 | Dynamic rate heartbeating for inter-node status updating |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/959,568 US8667126B2 (en) | 2010-12-03 | 2010-12-03 | Dynamic rate heartbeating for inter-node status updating |
| US13/425,666 US9219621B2 (en) | 2010-12-03 | 2012-03-21 | Dynamic rate heartbeating for inter-node status updating |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/959,568 Continuation US8667126B2 (en) | 2010-12-03 | 2010-12-03 | Dynamic rate heartbeating for inter-node status updating |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20120203898A1 US20120203898A1 (en) | 2012-08-09 |
| US9219621B2 true US9219621B2 (en) | 2015-12-22 |
Family
ID=46163296
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/959,568 Active 2031-12-04 US8667126B2 (en) | 2010-12-03 | 2010-12-03 | Dynamic rate heartbeating for inter-node status updating |
| US13/425,666 Expired - Fee Related US9219621B2 (en) | 2010-12-03 | 2012-03-21 | Dynamic rate heartbeating for inter-node status updating |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/959,568 Active 2031-12-04 US8667126B2 (en) | 2010-12-03 | 2010-12-03 | Dynamic rate heartbeating for inter-node status updating |
Country Status (1)
| Country | Link |
|---|---|
| US (2) | US8667126B2 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10382338B2 (en) * | 2014-08-22 | 2019-08-13 | Fujitsu Limited | Mitigation of processing load on control device controlling transfer devices within network |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120066694A1 (en) | 2010-09-10 | 2012-03-15 | International Business Machines Corporation | Event overflow handling by coalescing and updating previously-queued event notification |
| US8694625B2 (en) | 2010-09-10 | 2014-04-08 | International Business Machines Corporation | Selective registration for remote event notifications in processing node clusters |
| US8984119B2 (en) | 2010-11-05 | 2015-03-17 | International Business Machines Corporation | Changing an event identifier of a transient event in an event notification system |
| US8433760B2 (en) * | 2010-12-03 | 2013-04-30 | International Business Machines Corporation | Inter-node communication scheme for node status sharing |
| US8634328B2 (en) | 2010-12-03 | 2014-01-21 | International Business Machines Corporation | Endpoint-to-endpoint communications status monitoring |
| US8667126B2 (en) | 2010-12-03 | 2014-03-04 | International Business Machines Corporation | Dynamic rate heartbeating for inter-node status updating |
| US8634330B2 (en) | 2011-04-04 | 2014-01-21 | International Business Machines Corporation | Inter-cluster communications technique for event and health status communications |
| CN103428011B (en) * | 2012-05-16 | 2016-03-09 | 深圳市腾讯计算机系统有限公司 | Node state detection method, system and device in a kind of distributed system |
| EP3024394A4 (en) * | 2013-07-22 | 2017-03-22 | Quvium UK Ltd | Cough detection, analysis, and communication platform |
| US10356494B2 (en) * | 2014-05-07 | 2019-07-16 | Sikorsky Aircraft Corporation | Wireless sensor system with dynamic heartbeat message rate |
| US10657119B1 (en) * | 2015-12-18 | 2020-05-19 | Amazon Technologies, Inc. | Fleet node management system |
| US10439930B2 (en) * | 2017-04-26 | 2019-10-08 | Futurewei Technologies, Inc. | Packet batch processing with graph-path based pre-classification |
| CN108153606A (en) * | 2018-01-26 | 2018-06-12 | 上海储迅信息技术有限公司 | A kind of irredundant protection cluster realizes front-end business continuity method |
| US11336683B2 (en) * | 2019-10-16 | 2022-05-17 | Citrix Systems, Inc. | Systems and methods for preventing replay attacks |
| US11645175B2 (en) * | 2021-02-12 | 2023-05-09 | Commvault Systems, Inc. | Automatic failover of a storage manager |
| CN115333983B (en) * | 2022-08-16 | 2023-10-10 | 超聚变数字技术有限公司 | Heartbeat management method and node |
Citations (82)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6031817A (en) | 1996-12-23 | 2000-02-29 | Cascade Communications Corporation | System and method for providing notification of malfunctions in a digital data network |
| US6038563A (en) | 1997-10-31 | 2000-03-14 | Sun Microsystems, Inc. | System and method for restricting database access to managed object information using a permissions table that specifies access rights corresponding to user access rights to the managed objects |
| US6064656A (en) | 1997-10-31 | 2000-05-16 | Sun Microsystems, Inc. | Distributed system and method for controlling access control to network resources |
| US6185613B1 (en) | 1996-03-15 | 2001-02-06 | Netvision, Inc. | System and method for global event notification and delivery in a distributed computing environment |
| US6411967B1 (en) * | 1999-06-18 | 2002-06-25 | Reliable Network Solutions | Distributed processing system with replicated management information base |
| US20020178275A1 (en) | 2001-03-14 | 2002-11-28 | Hein Trent R. | Algorithm for prioritization of event datum in generic asynchronous telemetric streams |
| US20030061340A1 (en) * | 2001-09-25 | 2003-03-27 | Mingqiu Sun | Network health monitoring through real-time analysis of heartbeat patterns from distributed agents |
| US20030088831A1 (en) | 2001-10-18 | 2003-05-08 | Mathias Bauer | Method and system for managing documents modified while being viewed in a browser window |
| US20030093516A1 (en) | 2001-10-31 | 2003-05-15 | Parsons Anthony G.J. | Enterprise management event message format |
| US20030105801A1 (en) | 2001-11-30 | 2003-06-05 | Telefonaktiebolaget L M Ericsson (Publ) (Signed) | Method, system and agent for connecting event consumers to event producers in a distributed event management system |
| US6591317B1 (en) | 2000-05-12 | 2003-07-08 | 3Com Corporation | Queue incorporating a duplicate counter per entry |
| US6631363B1 (en) | 1999-10-11 | 2003-10-07 | I2 Technologies Us, Inc. | Rules-based notification system |
| US20030225840A1 (en) | 2002-05-28 | 2003-12-04 | Glassco David H.J. | Change notification and update service for object sharing via publication and subscription |
| US20030233594A1 (en) | 2002-06-12 | 2003-12-18 | Earl William J. | System and method for monitoring the state and operability of components in distributed computing systems |
| US20040008727A1 (en) | 2002-06-27 | 2004-01-15 | Michael See | Network resource management in a network device |
| US20040030775A1 (en) | 2002-08-08 | 2004-02-12 | International Business Machines Corporation | System and method for distributing management events to external processes |
| US20040064835A1 (en) | 2002-09-26 | 2004-04-01 | International Business Machines Corporation | System and method for content based on-demand video media overlay |
| US6778504B2 (en) | 2002-12-13 | 2004-08-17 | Alcatel Canada Inc. | Dynamic soft permanent virtual circuit bulk connection tracing |
| US20040172467A1 (en) | 2003-02-28 | 2004-09-02 | Gabriel Wechter | Method and system for monitoring a network |
| US6862619B1 (en) | 1999-09-10 | 2005-03-01 | Hitachi, Ltd. | Network management system equipped with event control means and method |
| US20050050098A1 (en) | 2003-09-03 | 2005-03-03 | Paul Barnett | System and method for aligning data frames in time |
| US20050065953A1 (en) | 2003-09-19 | 2005-03-24 | Bower Shelley K. | System and method for changing defined elements in a previously compiled program using a description file |
| US20050076145A1 (en) | 2003-10-07 | 2005-04-07 | Microsoft Corporation | Supporting point-to-point intracluster communications between replicated cluster nodes |
| US20050152396A1 (en) | 2002-06-24 | 2005-07-14 | Roman Pichna | Ad hoc networking of terminals aided by a cellular network |
| US20050210128A1 (en) * | 2004-03-16 | 2005-09-22 | Cannon David M | Apparatus, system, and method for adaptive polling of monitored systems |
| US20050234929A1 (en) | 2004-03-31 | 2005-10-20 | Ionescu Mihai F | Methods and systems for interfacing applications with a search engine |
| US6983324B1 (en) * | 2000-10-23 | 2006-01-03 | International Business Machines Corporation | Dynamic modification of cluster communication parameters in clustered computer system |
| US20060031282A1 (en) | 2000-12-18 | 2006-02-09 | Timothy Tuttle | Techniques for updating live objects at clients using a dynamic routing network |
| US20060050629A1 (en) | 2004-09-04 | 2006-03-09 | Nobuyuki Saika | Fail over method and a computing system having fail over function |
| US7058957B1 (en) | 2002-07-12 | 2006-06-06 | 3Pardata, Inc. | Cluster event notification system |
| US20060242155A1 (en) * | 2005-04-20 | 2006-10-26 | Microsoft Corporation | Systems and methods for providing distributed, decentralized data storage and retrieval |
| US20070041328A1 (en) | 2005-08-19 | 2007-02-22 | Bell Robert J Iv | Devices and methods of using link status to determine node availability |
| US20070140243A1 (en) | 2005-12-16 | 2007-06-21 | Bryant Eastham | Systems and methods for selecting a transport mechanism for communication in a network |
| US20070226182A1 (en) | 2006-03-21 | 2007-09-27 | Sobotka David C | Matching engine for comparing data feeds with user profile criteria |
| US20070271276A1 (en) * | 2006-05-03 | 2007-11-22 | Cassatt Corporation | Autonomic management of autonomous management systems |
| US20070282959A1 (en) | 2006-06-02 | 2007-12-06 | Stern Donald S | Message push with pull of information to a communications computing device |
| US20080008106A1 (en) | 2004-12-22 | 2008-01-10 | Christer Boberg | Method and Arrangement for Providing Communication Group Information to a Client |
| US20080077635A1 (en) | 2006-09-22 | 2008-03-27 | Digital Bazaar, Inc. | Highly Available Clustered Storage Network |
| US20080097628A1 (en) * | 2006-10-20 | 2008-04-24 | Rockwell Automation Technologies, Inc. | Automatic fault tuning |
| US20080183857A1 (en) | 2007-01-31 | 2008-07-31 | Ibm Corporation | Method and Apparatus for Providing Transparent Network Connectivity |
| US7451359B1 (en) | 2002-11-27 | 2008-11-11 | Oracle International Corp. | Heartbeat mechanism for cluster systems |
| US20080317050A1 (en) | 2007-06-21 | 2008-12-25 | Microsoft Corporation | Hybrid Tree/Mesh Overlay for Data Delivery |
| US20090070617A1 (en) | 2007-09-11 | 2009-03-12 | Arimilli Lakshminarayana B | Method for Providing a Cluster-Wide System Clock in a Multi-Tiered Full-Graph Interconnect Architecture |
| US7539755B2 (en) | 2006-04-24 | 2009-05-26 | Inventec Corporation | Real-time heartbeat frequency regulation system and method utilizing user-requested frequency |
| US20090138808A1 (en) | 2003-09-05 | 2009-05-28 | Groove Networks, Inc. | Method and apparatus for providing attributes of a collaboration system in an operating system folder-based file system |
| US7542437B1 (en) | 2003-10-02 | 2009-06-02 | Bbn Technologies Corp. | Systems and methods for conserving energy in a communications network |
| US7571230B2 (en) | 2004-10-29 | 2009-08-04 | International Business Machines Corporation | Method and system for monitoring server events in a node configuration by using direct communication between servers |
| US20090199051A1 (en) | 2008-01-31 | 2009-08-06 | Joefon Jann | Method and apparatus for operating system event notification mechanism using file system interface |
| US7624194B2 (en) | 2004-10-22 | 2009-11-24 | Microsoft Corporation | Establishing membership within a federation infrastructure |
| US7650404B2 (en) | 1999-02-23 | 2010-01-19 | Microsoft Corporation | Method and mechanism for providing computer programs with computer system events |
| US7664125B1 (en) | 2006-01-03 | 2010-02-16 | Emc Corporation | Indication forwarding in a distributed environment |
| US20100077310A1 (en) | 2003-10-23 | 2010-03-25 | Microsoft Corporation | Flexible architecture for notifying applications of state changes |
| US20100094922A1 (en) | 2008-10-15 | 2010-04-15 | Sailesh Kumar Sathish | Method, apparatus and computer program product for enabling dual mode communication |
| US20100099447A1 (en) | 2006-12-14 | 2010-04-22 | Christer Boberg | Method and Apparatus for Use in a Communications Network |
| US20100113072A1 (en) | 2008-10-31 | 2010-05-06 | Stubhub, Inc. | System and methods for upcoming event notification and mobile purchasing |
| US7738364B2 (en) | 2004-03-10 | 2010-06-15 | William L Bain | Scalable, highly available cluster membership architecture |
| US20100153528A1 (en) | 2008-12-16 | 2010-06-17 | At&T Intellectual Property I, L.P. | Devices, Systems and Methods for Controlling Network Services Via Address Book |
| US20100223492A1 (en) | 2009-01-20 | 2010-09-02 | Maria Farrugia | Node failure detection system and method for sip sessions in communication networks |
| US20100274885A1 (en) | 2009-04-22 | 2010-10-28 | Microsoft Corporation | Proactive load balancing |
| US20100281304A1 (en) | 2009-04-29 | 2010-11-04 | Moyer William C | Debug messaging with selective timestamp control |
| US20100290469A1 (en) | 2009-05-13 | 2010-11-18 | Avaya Inc. | Method and apparatus for providing fast reroute of a unicast packet within a network element to an available port associated with a multi-link trunk |
| US7856480B2 (en) | 2002-03-07 | 2010-12-21 | Cisco Technology, Inc. | Method and apparatus for exchanging heartbeat messages and configuration information between nodes operating in a master-slave configuration |
| US20100332277A1 (en) | 2009-06-26 | 2010-12-30 | Sap Ag | Method, article and system for consolidated change management |
| US20110035462A1 (en) | 2009-08-06 | 2011-02-10 | Sling Media Pvt Ltd | Systems and methods for event programming via a remote media player |
| US20110041140A1 (en) | 2009-08-13 | 2011-02-17 | Google Inc. | Event-Triggered Server-Side Macros |
| US7913105B1 (en) | 2006-09-29 | 2011-03-22 | Symantec Operating Corporation | High availability cluster with notification of resource state changes |
| US20110093743A1 (en) | 2008-01-30 | 2011-04-21 | International Business Machines Corporation | Method and System of Updating a Plurality of Computers |
| US20110145639A1 (en) | 2009-12-14 | 2011-06-16 | Sonus Networks, Inc. | Method and Apparatus For Controlling Traffic Entry In A Managed Packet Network |
| US20110202500A1 (en) | 2010-02-15 | 2011-08-18 | Bank Of America Corporation | Anomalous activity detection |
| US20110246460A1 (en) * | 2010-03-31 | 2011-10-06 | Cloudera, Inc. | Collecting and aggregating datasets for analysis |
| US20110274053A1 (en) | 2010-05-06 | 2011-11-10 | Qualcomm Incorporated | System and method for controlling downlink packet latency |
| US8108715B1 (en) | 2010-07-02 | 2012-01-31 | Symantec Corporation | Systems and methods for resolving split-brain scenarios in computer clusters |
| US20120036250A1 (en) | 2010-08-06 | 2012-02-09 | Silver Spring Networks, Inc. | System, Method and Program for Detecting Anomalous Events in a Utility Network |
| US20120047257A1 (en) | 2009-05-05 | 2012-02-23 | Suboti, Llc | System and method for processing user interface events |
| US8161053B1 (en) | 2004-03-31 | 2012-04-17 | Google Inc. | Methods and systems for eliminating duplicate events |
| US20120144018A1 (en) | 2010-12-03 | 2012-06-07 | International Business Machines Corporation | Dynamic Rate Heartbeating for Inter-Node Status Updating |
| US20120203899A1 (en) | 2010-12-03 | 2012-08-09 | International Business Machines Corporation | Inter-node communication scheme for node status sharing |
| US20120203897A1 (en) | 2010-12-03 | 2012-08-09 | International Business Machines Corporation | Endpoint-to-endpoint communications status monitoring |
| US20130042001A1 (en) | 2008-09-29 | 2013-02-14 | Christopher M. Gould | Event queues |
| US8384549B2 (en) | 2005-10-31 | 2013-02-26 | Honeywell International, Inc. | Event communication system for providing user alerts |
| US8484472B2 (en) | 2006-10-30 | 2013-07-09 | Research In Motion Limited | System and method of filtering unsolicited messages |
| US8634330B2 (en) | 2011-04-04 | 2014-01-21 | International Business Machines Corporation | Inter-cluster communications technique for event and health status communications |
-
2010
- 2010-12-03 US US12/959,568 patent/US8667126B2/en active Active
-
2012
- 2012-03-21 US US13/425,666 patent/US9219621B2/en not_active Expired - Fee Related
Patent Citations (85)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6185613B1 (en) | 1996-03-15 | 2001-02-06 | Netvision, Inc. | System and method for global event notification and delivery in a distributed computing environment |
| US6031817A (en) | 1996-12-23 | 2000-02-29 | Cascade Communications Corporation | System and method for providing notification of malfunctions in a digital data network |
| US6038563A (en) | 1997-10-31 | 2000-03-14 | Sun Microsystems, Inc. | System and method for restricting database access to managed object information using a permissions table that specifies access rights corresponding to user access rights to the managed objects |
| US6064656A (en) | 1997-10-31 | 2000-05-16 | Sun Microsystems, Inc. | Distributed system and method for controlling access control to network resources |
| US7650404B2 (en) | 1999-02-23 | 2010-01-19 | Microsoft Corporation | Method and mechanism for providing computer programs with computer system events |
| US6411967B1 (en) * | 1999-06-18 | 2002-06-25 | Reliable Network Solutions | Distributed processing system with replicated management information base |
| US6862619B1 (en) | 1999-09-10 | 2005-03-01 | Hitachi, Ltd. | Network management system equipped with event control means and method |
| US6631363B1 (en) | 1999-10-11 | 2003-10-07 | I2 Technologies Us, Inc. | Rules-based notification system |
| US6591317B1 (en) | 2000-05-12 | 2003-07-08 | 3Com Corporation | Queue incorporating a duplicate counter per entry |
| US6983324B1 (en) * | 2000-10-23 | 2006-01-03 | International Business Machines Corporation | Dynamic modification of cluster communication parameters in clustered computer system |
| US20060031282A1 (en) | 2000-12-18 | 2006-02-09 | Timothy Tuttle | Techniques for updating live objects at clients using a dynamic routing network |
| US20020178275A1 (en) | 2001-03-14 | 2002-11-28 | Hein Trent R. | Algorithm for prioritization of event datum in generic asynchronous telemetric streams |
| US20030061340A1 (en) * | 2001-09-25 | 2003-03-27 | Mingqiu Sun | Network health monitoring through real-time analysis of heartbeat patterns from distributed agents |
| US20030088831A1 (en) | 2001-10-18 | 2003-05-08 | Mathias Bauer | Method and system for managing documents modified while being viewed in a browser window |
| US20030093516A1 (en) | 2001-10-31 | 2003-05-15 | Parsons Anthony G.J. | Enterprise management event message format |
| US20030105801A1 (en) | 2001-11-30 | 2003-06-05 | Telefonaktiebolaget L M Ericsson (Publ) (Signed) | Method, system and agent for connecting event consumers to event producers in a distributed event management system |
| US7856480B2 (en) | 2002-03-07 | 2010-12-21 | Cisco Technology, Inc. | Method and apparatus for exchanging heartbeat messages and configuration information between nodes operating in a master-slave configuration |
| US20030225840A1 (en) | 2002-05-28 | 2003-12-04 | Glassco David H.J. | Change notification and update service for object sharing via publication and subscription |
| US20030233594A1 (en) | 2002-06-12 | 2003-12-18 | Earl William J. | System and method for monitoring the state and operability of components in distributed computing systems |
| US20050152396A1 (en) | 2002-06-24 | 2005-07-14 | Roman Pichna | Ad hoc networking of terminals aided by a cellular network |
| US20040008727A1 (en) | 2002-06-27 | 2004-01-15 | Michael See | Network resource management in a network device |
| US7058957B1 (en) | 2002-07-12 | 2006-06-06 | 3Pardata, Inc. | Cluster event notification system |
| US20040030775A1 (en) | 2002-08-08 | 2004-02-12 | International Business Machines Corporation | System and method for distributing management events to external processes |
| US20040064835A1 (en) | 2002-09-26 | 2004-04-01 | International Business Machines Corporation | System and method for content based on-demand video media overlay |
| US7590898B2 (en) | 2002-11-27 | 2009-09-15 | Oracle International Corp. | Heartbeat mechanism for cluster systems |
| US20090043887A1 (en) * | 2002-11-27 | 2009-02-12 | Oracle International Corporation | Heartbeat mechanism for cluster systems |
| US7451359B1 (en) | 2002-11-27 | 2008-11-11 | Oracle International Corp. | Heartbeat mechanism for cluster systems |
| US6778504B2 (en) | 2002-12-13 | 2004-08-17 | Alcatel Canada Inc. | Dynamic soft permanent virtual circuit bulk connection tracing |
| US20040172467A1 (en) | 2003-02-28 | 2004-09-02 | Gabriel Wechter | Method and system for monitoring a network |
| US20050050098A1 (en) | 2003-09-03 | 2005-03-03 | Paul Barnett | System and method for aligning data frames in time |
| US20090138808A1 (en) | 2003-09-05 | 2009-05-28 | Groove Networks, Inc. | Method and apparatus for providing attributes of a collaboration system in an operating system folder-based file system |
| US20050065953A1 (en) | 2003-09-19 | 2005-03-24 | Bower Shelley K. | System and method for changing defined elements in a previously compiled program using a description file |
| US7542437B1 (en) | 2003-10-02 | 2009-06-02 | Bbn Technologies Corp. | Systems and methods for conserving energy in a communications network |
| US20050076145A1 (en) | 2003-10-07 | 2005-04-07 | Microsoft Corporation | Supporting point-to-point intracluster communications between replicated cluster nodes |
| US20100077310A1 (en) | 2003-10-23 | 2010-03-25 | Microsoft Corporation | Flexible architecture for notifying applications of state changes |
| US7738364B2 (en) | 2004-03-10 | 2010-06-15 | William L Bain | Scalable, highly available cluster membership architecture |
| US20050210128A1 (en) * | 2004-03-16 | 2005-09-22 | Cannon David M | Apparatus, system, and method for adaptive polling of monitored systems |
| US8161053B1 (en) | 2004-03-31 | 2012-04-17 | Google Inc. | Methods and systems for eliminating duplicate events |
| US20050234929A1 (en) | 2004-03-31 | 2005-10-20 | Ionescu Mihai F | Methods and systems for interfacing applications with a search engine |
| US20060050629A1 (en) | 2004-09-04 | 2006-03-09 | Nobuyuki Saika | Fail over method and a computing system having fail over function |
| US7624194B2 (en) | 2004-10-22 | 2009-11-24 | Microsoft Corporation | Establishing membership within a federation infrastructure |
| US7571230B2 (en) | 2004-10-29 | 2009-08-04 | International Business Machines Corporation | Method and system for monitoring server events in a node configuration by using direct communication between servers |
| US20080008106A1 (en) | 2004-12-22 | 2008-01-10 | Christer Boberg | Method and Arrangement for Providing Communication Group Information to a Client |
| US20060242155A1 (en) * | 2005-04-20 | 2006-10-26 | Microsoft Corporation | Systems and methods for providing distributed, decentralized data storage and retrieval |
| US20070041328A1 (en) | 2005-08-19 | 2007-02-22 | Bell Robert J Iv | Devices and methods of using link status to determine node availability |
| US8384549B2 (en) | 2005-10-31 | 2013-02-26 | Honeywell International, Inc. | Event communication system for providing user alerts |
| US20070140243A1 (en) | 2005-12-16 | 2007-06-21 | Bryant Eastham | Systems and methods for selecting a transport mechanism for communication in a network |
| US7664125B1 (en) | 2006-01-03 | 2010-02-16 | Emc Corporation | Indication forwarding in a distributed environment |
| US20070226182A1 (en) | 2006-03-21 | 2007-09-27 | Sobotka David C | Matching engine for comparing data feeds with user profile criteria |
| US7539755B2 (en) | 2006-04-24 | 2009-05-26 | Inventec Corporation | Real-time heartbeat frequency regulation system and method utilizing user-requested frequency |
| US20070271276A1 (en) * | 2006-05-03 | 2007-11-22 | Cassatt Corporation | Autonomic management of autonomous management systems |
| US20070282959A1 (en) | 2006-06-02 | 2007-12-06 | Stern Donald S | Message push with pull of information to a communications computing device |
| US20080077635A1 (en) | 2006-09-22 | 2008-03-27 | Digital Bazaar, Inc. | Highly Available Clustered Storage Network |
| US7913105B1 (en) | 2006-09-29 | 2011-03-22 | Symantec Operating Corporation | High availability cluster with notification of resource state changes |
| US20080097628A1 (en) * | 2006-10-20 | 2008-04-24 | Rockwell Automation Technologies, Inc. | Automatic fault tuning |
| US8484472B2 (en) | 2006-10-30 | 2013-07-09 | Research In Motion Limited | System and method of filtering unsolicited messages |
| US20100099447A1 (en) | 2006-12-14 | 2010-04-22 | Christer Boberg | Method and Apparatus for Use in a Communications Network |
| US20080183857A1 (en) | 2007-01-31 | 2008-07-31 | Ibm Corporation | Method and Apparatus for Providing Transparent Network Connectivity |
| US20080317050A1 (en) | 2007-06-21 | 2008-12-25 | Microsoft Corporation | Hybrid Tree/Mesh Overlay for Data Delivery |
| US20090070617A1 (en) | 2007-09-11 | 2009-03-12 | Arimilli Lakshminarayana B | Method for Providing a Cluster-Wide System Clock in a Multi-Tiered Full-Graph Interconnect Architecture |
| US20110093743A1 (en) | 2008-01-30 | 2011-04-21 | International Business Machines Corporation | Method and System of Updating a Plurality of Computers |
| US20090199051A1 (en) | 2008-01-31 | 2009-08-06 | Joefon Jann | Method and apparatus for operating system event notification mechanism using file system interface |
| US20130042001A1 (en) | 2008-09-29 | 2013-02-14 | Christopher M. Gould | Event queues |
| US20100094922A1 (en) | 2008-10-15 | 2010-04-15 | Sailesh Kumar Sathish | Method, apparatus and computer program product for enabling dual mode communication |
| US20100113072A1 (en) | 2008-10-31 | 2010-05-06 | Stubhub, Inc. | System and methods for upcoming event notification and mobile purchasing |
| US20100153528A1 (en) | 2008-12-16 | 2010-06-17 | At&T Intellectual Property I, L.P. | Devices, Systems and Methods for Controlling Network Services Via Address Book |
| US20100223492A1 (en) | 2009-01-20 | 2010-09-02 | Maria Farrugia | Node failure detection system and method for sip sessions in communication networks |
| US20100274885A1 (en) | 2009-04-22 | 2010-10-28 | Microsoft Corporation | Proactive load balancing |
| US20100281304A1 (en) | 2009-04-29 | 2010-11-04 | Moyer William C | Debug messaging with selective timestamp control |
| US20120047257A1 (en) | 2009-05-05 | 2012-02-23 | Suboti, Llc | System and method for processing user interface events |
| US20100290469A1 (en) | 2009-05-13 | 2010-11-18 | Avaya Inc. | Method and apparatus for providing fast reroute of a unicast packet within a network element to an available port associated with a multi-link trunk |
| US20100332277A1 (en) | 2009-06-26 | 2010-12-30 | Sap Ag | Method, article and system for consolidated change management |
| US20110035462A1 (en) | 2009-08-06 | 2011-02-10 | Sling Media Pvt Ltd | Systems and methods for event programming via a remote media player |
| US20110041140A1 (en) | 2009-08-13 | 2011-02-17 | Google Inc. | Event-Triggered Server-Side Macros |
| US20110145639A1 (en) | 2009-12-14 | 2011-06-16 | Sonus Networks, Inc. | Method and Apparatus For Controlling Traffic Entry In A Managed Packet Network |
| US20110202500A1 (en) | 2010-02-15 | 2011-08-18 | Bank Of America Corporation | Anomalous activity detection |
| US20110246460A1 (en) * | 2010-03-31 | 2011-10-06 | Cloudera, Inc. | Collecting and aggregating datasets for analysis |
| US20110274053A1 (en) | 2010-05-06 | 2011-11-10 | Qualcomm Incorporated | System and method for controlling downlink packet latency |
| US8108715B1 (en) | 2010-07-02 | 2012-01-31 | Symantec Corporation | Systems and methods for resolving split-brain scenarios in computer clusters |
| US20120036250A1 (en) | 2010-08-06 | 2012-02-09 | Silver Spring Networks, Inc. | System, Method and Program for Detecting Anomalous Events in a Utility Network |
| US20120144018A1 (en) | 2010-12-03 | 2012-06-07 | International Business Machines Corporation | Dynamic Rate Heartbeating for Inter-Node Status Updating |
| US20120203899A1 (en) | 2010-12-03 | 2012-08-09 | International Business Machines Corporation | Inter-node communication scheme for node status sharing |
| US20120203897A1 (en) | 2010-12-03 | 2012-08-09 | International Business Machines Corporation | Endpoint-to-endpoint communications status monitoring |
| US8433760B2 (en) | 2010-12-03 | 2013-04-30 | International Business Machines Corporation | Inter-node communication scheme for node status sharing |
| US8634330B2 (en) | 2011-04-04 | 2014-01-21 | International Business Machines Corporation | Inter-cluster communications technique for event and health status communications |
Non-Patent Citations (4)
| Title |
|---|
| Notice of Allowance in U.S. Appl. No. 12/959,568 mailed on Oct. 17, 2013, 11 pages (pp. 1-11 in pdf). |
| Office Action in U.S. Appl. No. 12/959,568 mailed on Jun. 10, 2013, 15 pages (pp. 1-15 in pdf). |
| Office Action in U.S. Appl. No. 12/959,568 mailed on Nov. 27, 2012, 17 pages (pp. 1-17 in pdf). |
| Van Renesse, et al., "A gossip-style failure detection service", Proceedings of the IFIP International Conference on Distributed Systems Platforms and Open Distributed Processing, 2009, Springer Verlag, Illinois. |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10382338B2 (en) * | 2014-08-22 | 2019-08-13 | Fujitsu Limited | Mitigation of processing load on control device controlling transfer devices within network |
Also Published As
| Publication number | Publication date |
|---|---|
| US8667126B2 (en) | 2014-03-04 |
| US20120203898A1 (en) | 2012-08-09 |
| US20120144018A1 (en) | 2012-06-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9219621B2 (en) | Dynamic rate heartbeating for inter-node status updating | |
| US8634328B2 (en) | Endpoint-to-endpoint communications status monitoring | |
| US8806007B2 (en) | Inter-node communication scheme for node status sharing | |
| JP5666685B2 (en) | Failure analysis apparatus, system thereof, and method thereof | |
| US6704284B1 (en) | Management system and method for monitoring stress in a network | |
| JP3593528B2 (en) | Distributed network management system and method | |
| CN115428368A (en) | System and method for remote collaboration | |
| EP3033860B1 (en) | Transparent software-defined network management | |
| US8634330B2 (en) | Inter-cluster communications technique for event and health status communications | |
| CN103416022B (en) | Throughput testing approach and system in service in distribution router/exchange board structure | |
| US6633230B2 (en) | Apparatus and method for providing improved stress thresholds in network management systems | |
| US20110055311A1 (en) | Method of autonomic representative selection in local area networks | |
| CN101681347A (en) | probing network nodes for optimization | |
| US11902362B2 (en) | Topology-aware load balancing method and apparatus, and computer device | |
| US9621438B2 (en) | Network traffic management | |
| US20180278484A1 (en) | Storage area network diagnostic data | |
| JP2000134203A (en) | Network management system and its management method | |
| WO2022162465A1 (en) | Systems and methods for the temporal monitoring and visualization of network health of direct interconnect networks | |
| EP3985922A1 (en) | Cooperative power management | |
| CN113300914A (en) | Network quality monitoring method, device, system, electronic equipment and storage medium | |
| CN109756384B (en) | Data source state determination method and device and computer readable storage medium | |
| Iri et al. | Congestion-adaptive data collection with accuracy guarantee in cyber-physical systems | |
| CN108964955A (en) | A kind of loss Trap message lookup method and Network Management System and a kind of SNMP agent | |
| CN116647465A (en) | Automatic operation and maintenance method based on artificial intelligence technology | |
| US20030149786A1 (en) | Efficient counter retrieval |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |
|
| FEPP | Fee payment procedure |
Free format text: MAINTENANCE FEE REMINDER MAILED (ORIGINAL EVENT CODE: REM.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| LAPS | Lapse for failure to pay maintenance fees |
Free format text: PATENT EXPIRED FOR FAILURE TO PAY MAINTENANCE FEES (ORIGINAL EVENT CODE: EXP.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| STCH | Information on status: patent discontinuation |
Free format text: PATENT EXPIRED DUE TO NONPAYMENT OF MAINTENANCE FEES UNDER 37 CFR 1.362 |
|
| FP | Lapsed due to failure to pay maintenance fee |
Effective date: 20191222 |